
 零基础入门SparkDataFrame与SparkSQL的由来 Hive+Spark强强联合:分布式数仓的不二之选 RDD常用算子(二):Spark如何实现数据聚合? RDD常用算子(三):数据的准备、重分布与持久化 RDD常用算子(一):RDD内部的数据转换 RDD与编程模型:延迟计算是怎么回事? Shuffle管理:为什么Shuffle是性能瓶颈? Spark:从“大数据的HelloWorld”开始 SparkMLlib:从“房价预测”开始 SparkMLlibPipeline:高效开发机器学习应用 SparkUI(上):如何高效地定位性能问题? SparkUI(下):如何高效地定位性能问题? 存储系统:数据到底都存哪儿了? 广播变量&累加器:共享变量是用来做什么的? 广播变量-累加器:共享变量是用来做什么的? 基础配置详解:有哪些配置项是你必须要关注的? 进程模型与分布式部署:分布式计算是怎么回事? 模型训练(上):决策树系列算法详解 模型训练(下):协同过滤与频繁项集算法详解 模型训练(中):回归、分类和聚类算法详解 内存管理:Spark如何使用内存? 配置项详解:哪些参数会影响应用程序执行性能? 让我们从《小汽车摇号分析》开始 数据关联:不同的关联形式与实现机制该怎么选? 数据关联优化:都有哪些Join策略,开发者该如何取舍? 数据源与数据格式:DataFrame从何而来? 数据转换:如何在DataFrame之上做数据处理? 特征工程(上):有哪些常用的特征处理函数? 特征工程(下):有哪些常用的特征处理函数? 调度系统:DAG、Stages与分布式任务
零基础入门SparkDataFrame与SparkSQL的由来 Hive+Spark强强联合:分布式数仓的不二之选 RDD常用算子(二):Spark如何实现数据聚合? RDD常用算子(三):数据的准备、重分布与持久化 RDD常用算子(一):RDD内部的数据转换 RDD与编程模型:延迟计算是怎么回事? Shuffle管理:为什么Shuffle是性能瓶颈? Spark:从“大数据的HelloWorld”开始 SparkMLlib:从“房价预测”开始 SparkMLlibPipeline:高效开发机器学习应用 SparkUI(上):如何高效地定位性能问题? SparkUI(下):如何高效地定位性能问题? 存储系统:数据到底都存哪儿了? 广播变量&累加器:共享变量是用来做什么的? 广播变量-累加器:共享变量是用来做什么的? 基础配置详解:有哪些配置项是你必须要关注的? 进程模型与分布式部署:分布式计算是怎么回事? 模型训练(上):决策树系列算法详解 模型训练(下):协同过滤与频繁项集算法详解 模型训练(中):回归、分类和聚类算法详解 内存管理:Spark如何使用内存? 配置项详解:哪些参数会影响应用程序执行性能? 让我们从《小汽车摇号分析》开始 数据关联:不同的关联形式与实现机制该怎么选? 数据关联优化:都有哪些Join策略,开发者该如何取舍? 数据源与数据格式:DataFrame从何而来? 数据转换:如何在DataFrame之上做数据处理? 特征工程(上):有哪些常用的特征处理函数? 特征工程(下):有哪些常用的特征处理函数? 调度系统:DAG、Stages与分布式任务 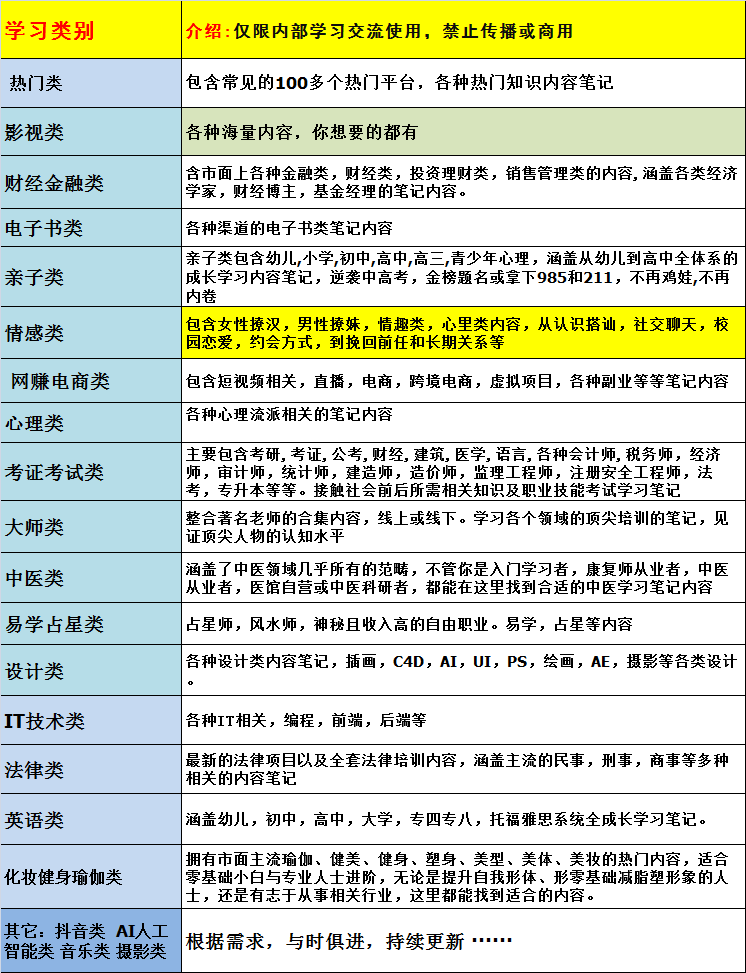
声明:本站大部分资源来源于网络,除本站组织的资源外,版权归原作者所有,如有侵犯版权,请立刻和本站联系并提供证据,本站将在三个工作日内改正。 本站仅提供学习的平台,将不对任何资源负法律责任,只作为购买原版的参考,并无法代替原版,所有资源请在下载后24小时内删除;资源版权归作者所有,如果您觉得满意,请购买正版。您若发现本站侵犯了你的版权利益,请来信本站将立即予以删除!















