
 NLP实战高手课A2C和A3C:如何提升基本的PolicyGradient算法 AlphaStar介绍:AlphaStar中采取了哪些技术? ASDL和AST AutoML及NeuralArchitectureSearch简介 AutoML网络架构举例 COMAAgent之间的交流 DeepGBM:如何用神经网络捕捉集成树模型的知识 DifferentiableSearch:如何将NAS变为可微的问题 DirectPolictyGradient:基本设定及Gumbel-trick的使用116丨DirectPolictyGradient:轨迹生成方法 Docker部署实践 Docker简介 Gumbel-trick:如何将离散的优化改变为连续的优化问题? ImitationLearning和Self-imitationLearning IMPALA:多Agent的Actor-Critic算法 InductiveLogicProgramming:基本设定 InductiveLogicProgramming:一个可微的实现 Istio简介:Istio包含哪些功能? Istio实例和Circuit Breaker Kubernetes Ingress Kubernetes Stateful Sets Kubernetes部署实践 Kubernetes服务发现 Kubernetes灰度上线 Kubernetes基本概念 Kubernetes健康检查 Kubernetes自动扩容 LambdaCaculus概述 Lambda-DCS概述 Learning to optimize:是否可以让机器学到一个新的优化器 LeNAS:如何搜索搜索space MCTS简介:如何将“推理”引入到强化学习框架中 Model-basedReinforcementLearning PolicyGradient:如何进行PolicyGradient的基本推导? PPO算法 Q-learning:如何进行Q-learning算法的推导? Quora问题等价性案例学习:深度学习模型 Quora问题等价性案例学习:预处理和人工特征 Rainbow:如何改进Q-learning算法? RENAS:如何使用遗传算法和增强学习探索网络架构 Reward设计的一般原则 RL训练方法RL实验的注意事项 RL训练方法集锦:简介 TransferReinforcementLearning和Few-shotReinforcementLearning Tranx简介 WikiSQL任务简介 层次搜索法:如何在模块之间进行搜索? 超参数搜索:如何寻找算法的超参数 多代理增强学习概述:什么是多代理增强学习? 多模态表示学习简介 解决SparseReward的一些方法 使用增强学习改进组合优化的算法 微服务和Kubernetes简介 文本推荐系统和增强学习 文本校对案例学习 遗传算法和增强学习的结合 增强学习的基本设定:增强学习与传统的预测性建模有什么区别? 增强学习中的探索问题 知识蒸馏:如何加速神经网络推理 最短路问题和DijkstraAlgorithm
NLP实战高手课A2C和A3C:如何提升基本的PolicyGradient算法 AlphaStar介绍:AlphaStar中采取了哪些技术? ASDL和AST AutoML及NeuralArchitectureSearch简介 AutoML网络架构举例 COMAAgent之间的交流 DeepGBM:如何用神经网络捕捉集成树模型的知识 DifferentiableSearch:如何将NAS变为可微的问题 DirectPolictyGradient:基本设定及Gumbel-trick的使用116丨DirectPolictyGradient:轨迹生成方法 Docker部署实践 Docker简介 Gumbel-trick:如何将离散的优化改变为连续的优化问题? ImitationLearning和Self-imitationLearning IMPALA:多Agent的Actor-Critic算法 InductiveLogicProgramming:基本设定 InductiveLogicProgramming:一个可微的实现 Istio简介:Istio包含哪些功能? Istio实例和Circuit Breaker Kubernetes Ingress Kubernetes Stateful Sets Kubernetes部署实践 Kubernetes服务发现 Kubernetes灰度上线 Kubernetes基本概念 Kubernetes健康检查 Kubernetes自动扩容 LambdaCaculus概述 Lambda-DCS概述 Learning to optimize:是否可以让机器学到一个新的优化器 LeNAS:如何搜索搜索space MCTS简介:如何将“推理”引入到强化学习框架中 Model-basedReinforcementLearning PolicyGradient:如何进行PolicyGradient的基本推导? PPO算法 Q-learning:如何进行Q-learning算法的推导? Quora问题等价性案例学习:深度学习模型 Quora问题等价性案例学习:预处理和人工特征 Rainbow:如何改进Q-learning算法? RENAS:如何使用遗传算法和增强学习探索网络架构 Reward设计的一般原则 RL训练方法RL实验的注意事项 RL训练方法集锦:简介 TransferReinforcementLearning和Few-shotReinforcementLearning Tranx简介 WikiSQL任务简介 层次搜索法:如何在模块之间进行搜索? 超参数搜索:如何寻找算法的超参数 多代理增强学习概述:什么是多代理增强学习? 多模态表示学习简介 解决SparseReward的一些方法 使用增强学习改进组合优化的算法 微服务和Kubernetes简介 文本推荐系统和增强学习 文本校对案例学习 遗传算法和增强学习的结合 增强学习的基本设定:增强学习与传统的预测性建模有什么区别? 增强学习中的探索问题 知识蒸馏:如何加速神经网络推理 最短路问题和DijkstraAlgorithm 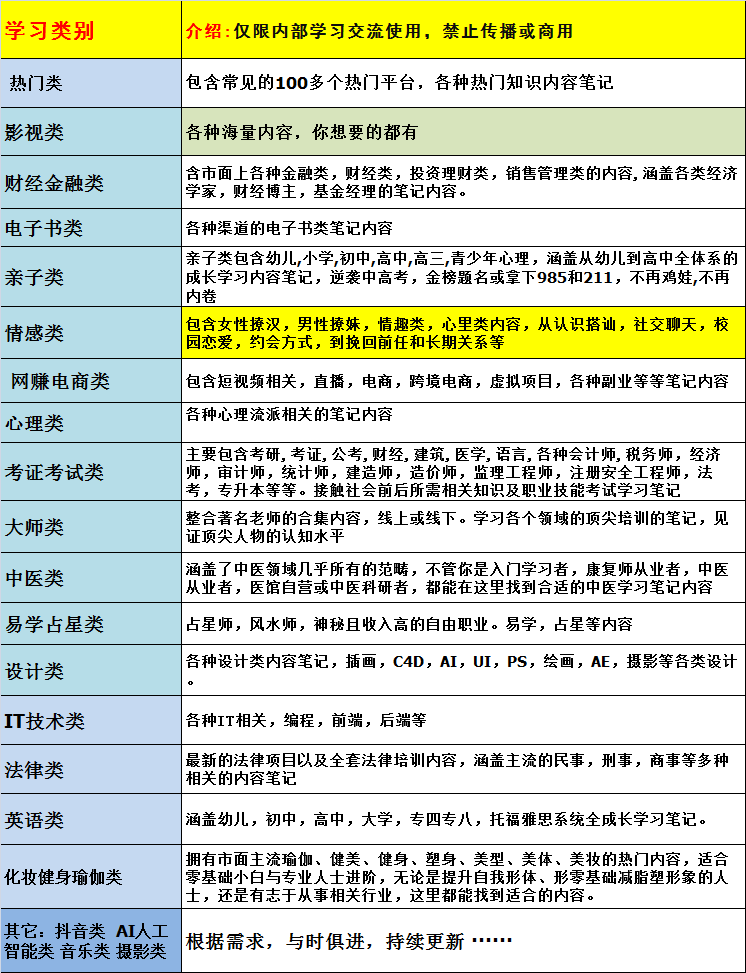
声明:本站大部分资源来源于网络,除本站组织的资源外,版权归原作者所有,如有侵犯版权,请立刻和本站联系并提供证据,本站将在三个工作日内改正。 本站仅提供学习的平台,将不对任何资源负法律责任,只作为购买原版的参考,并无法代替原版,所有资源请在下载后24小时内删除;资源版权归作者所有,如果您觉得满意,请购买正版。您若发现本站侵犯了你的版权利益,请来信本站将立即予以删除!















